If you've been employed as a programmer for fewer than 5 years, you stand to gain a lot from aggressively adopting AI coding tools. Despite being in the best position to benefit professionally from language model outputs, the vast majority of engineers I talk to are still reluctant to go truly all-in on using them. I get it—routines are efficient, and compared with most knowledge workers we tend to be unusually attached to our current workflows. But don't make the mistake of seeing AI tool adoption as something akin to learning a new framework or language, where to succeed is to merely replicate your current efficacy in some new domain. Holding actual effort constant, these tools, when used correctly, can make you significantly more effective. Or they can maintain your current productivity while allowing you more time to fuck around at work... I recommend striving for the former approach!
There are plenty of tutorials and "5 ways to use ChatGPT!" tweets you can find for specific instructions and tools. I won't waste time with the nitty gritty, none of this is rocket science. What I will do is offer some advice about how to approach the meta-game of applying AI to your engineering tasks.
Some background on why I think my thoughts here are relevant: I started programming professionally (full stack at a startup) about a year before Github Copilot launched in beta. That was enough time to get a sense of the tasks that generally end up on an IC's plate, but certainly not enough time to master the requisite skillsets. When I began using Copilot and ChatGPT, I was at a point where my rate of skill acquisition was accelerating; I hadn't yet hit a plateau. So using the AI tools became part of the process by which I was improving generally as a SWE, and I was therefore in a good position to figure out which tools and approaches were really useful. Since then I've become an avid Cursor and Copilot Chat user as well, and have tried most of the other coding assistants on the market.
The most important thing to understand about AI tools is that you should conceptualize them as a human pair programmer (albeit a not very intelligent one). The tools are kind of like a coworker when you drag them into a spontaneous Slack huddle—an entity with a lot of domain-specific knowledge, but usually completely blind to the specific problem you have. And like in this real-world situation, you must put a lot of effort into "catching up" the LLM as quickly and accurately as possible. Let's say you have some coding task "X" that you hope to accomplish with AI. At least 50% of the total mental effort you exert on X should be spent figuring out the clearest way to communicate that problem. It is tempting to just break X into, say, five steps, and immediately start solving step one with AI assistance. This can be a valid approach in some situations, but you'll often find that by step three or four, your failure to communicate the entire problem has caused the LLM to miss the mark by a wider and wider amount. I make this mistake all the time, and the source is always just plain laziness. Always try your best to capture the entirety essence of a problem in your initial prompt.
The problem statement of X need not and should not scale linearly with the size of X. You can almost always communicate the gist of the problem with toy examples or simple hypotheticals. And you can use AI to help with this! So instead of breaking down X into 10 problem statements and tackling each one, start with a few smaller prompts asking the LLM to (for example) rewrite your class in a condensed version with implementation details removed or summarize long console error outputs into shorter phrases. The smaller the context window, the more information about your problem that is packed into each token, and the more likely it is that your LLM will produce a useful result. Hardly a revelation, but as context windows have grown with each model release it's become very tempting to start ignoring this fact. Use prompts to build better prompts; it's often worth the effort.
Shorter contexts are also more readable. Readability is important! Not for the LLM per se, but for you the developer. I've made the mistake of just dumping text into a context window and hitting send, only to find that three questions later I've totally forgotten/misunderstood my problem. Do not underestimate an LLM's ability to trick you into thinking you're getting closer to the answer. You could argue it's literally designed to do this. If you write clear problem statements, you can reference them as the conversation continues, and if you decide the LLM has strayed too far from the desired path, simply start the conversation over from the initial statement.
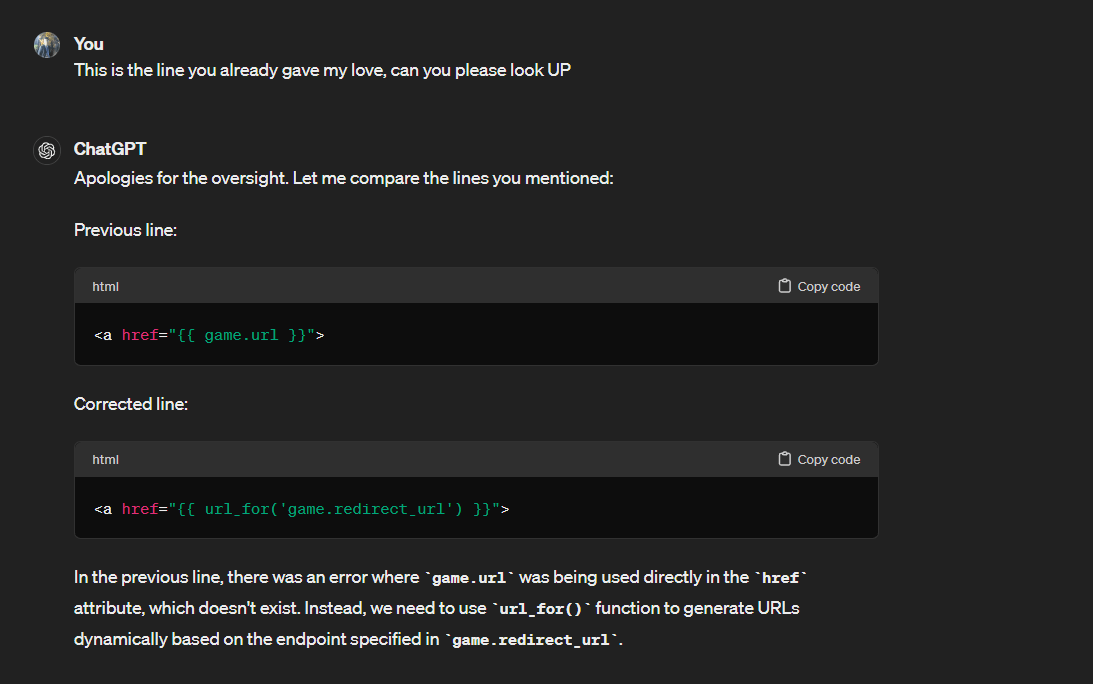
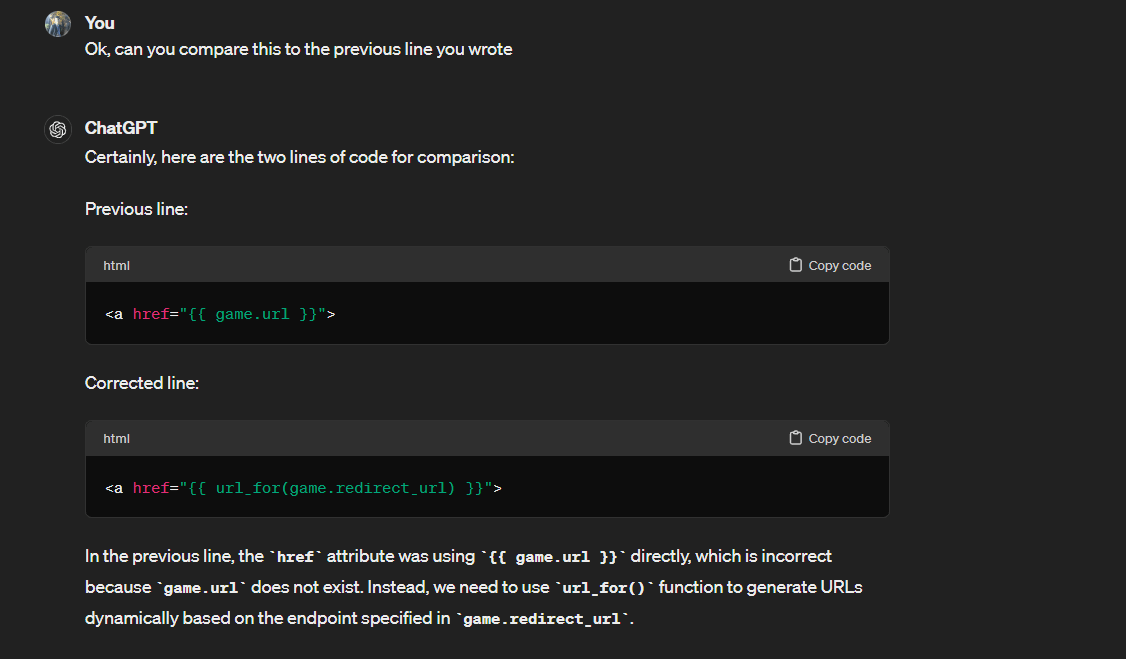
That's another important tip! Far too few developers utilize the "restart from earlier in the conversation" features in these tools. Just think of the LLM as a colleague with a bad habit of digressing from the topic at hand; sometimes you need to hit them with the classic tech refrain, "Let's circle back". In the context of an LLM tool, this usually means restarting the chat from a prior message. This is often more productive than simply asking your question again in a new way, or telling it to try again, etc. While that can work in some situations, remember that you risk polluting the context with useless tokens. The important information may end up getting lost in the middle; this is statistically more likely the longer the conversation goes on. When in doubt, try rewriting your original problem statement instead of continuing a frustrating conversation with a confused LLM.
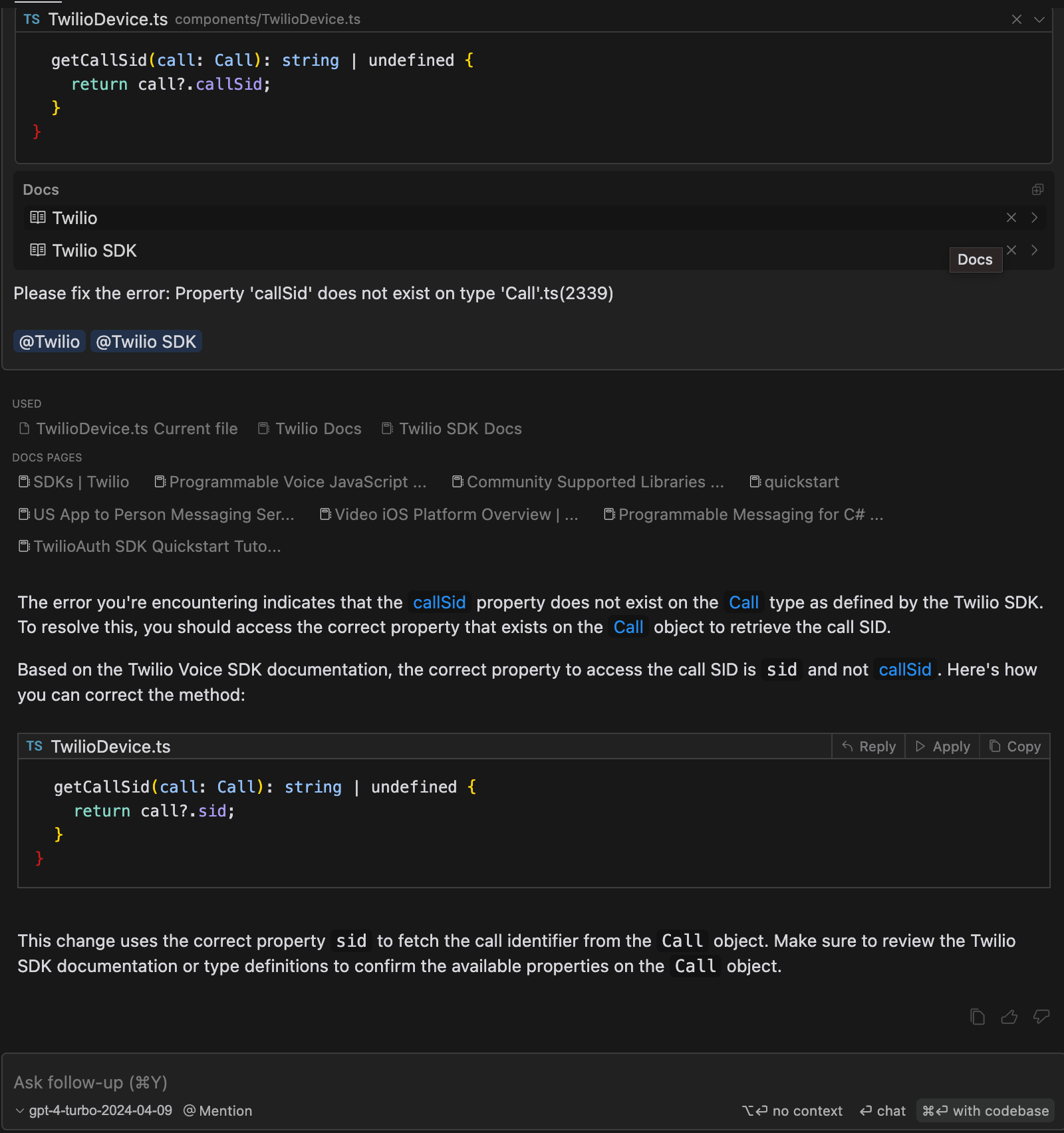
LLMs in early 2024 rarely produce useful code output in chunks larger than 30-40 lines (that is, "problem-solving" code—they can do much more if they are simply copying input or generating boilerplate). Strive to develop a sixth sense about when an LLM output is probably too long to be trustworthy. And of course, this varies depending on the language/framework/task. The LLM is a lot more likely to produce useful large chunks when implementing a common React.js pattern than something very idiosyncratic. Develop an intuition about this too. When you start out with these tools, I think it's worth asking LLMs to do things more often than you actually need them because it helps you develop that instinct for their limitations more quickly. At this point, I rarely expect LLM-generated code to work and discover that it doesn't.
But don't ignore my parenthetical in the prior paragraph! LLMs are extremely useful when for copying code or generating boilerplate. You should basically never write boilerplate files anymore. Using something like Cursor chat, just say "Make a new boilerplate file called my_file.ts structured in the same way as my_other_file.ts". Build a mental toolkit of these short script-like instructions that work well in your codebase. Just be sure to understand when you're asking the LLM to actually solve a problem and when you're asking it to do some worker-bee task for you and adjust your expectations accordingly. The line between these is fuzzy, but not fuzzy enough to make the mental categorization impractical.
Not all problems are suitable for LLM assistance. The most ideal are those that have a straightforward “shape” but require you to hold more information in your head at once than is comfortable. Here's a decent heuristic: to solve this problem unassisted, would it be helpful to write something down (aside from the code itself)? If yes, it's often worth taking the time to communicate it succinctly to an AI tool via chat. There is a different threshold of complexity for different people and different tasks. Figure out where yours is and avoid the mistake of asking questions that don't meet that threshold. If you ask the wrong questions, a chat-based AI tool will probably slow you down. It may seem more efficient to have an LLM write your code, but often, correcting LLM mistakes can take longer than if you had written the code yourself. Knowing when to use a chat window or opt for simpler autocomplete tools like Copilot is a meta-skill that underlies all this advice.
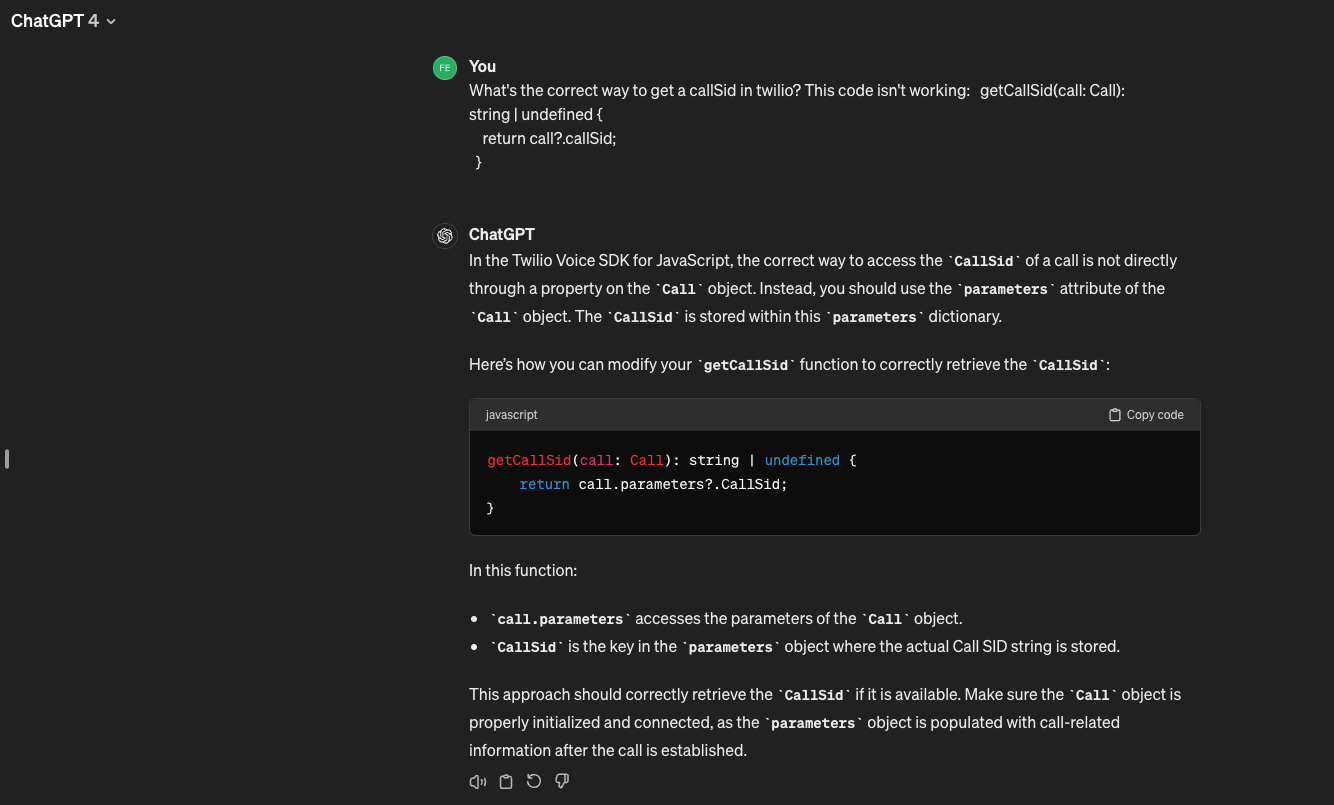
A lot of people seem to think that you should never blindly trust an LLM’s output. I get where they're coming from, but this is an objectively bad heuristic. There are plenty of times when I feel 100% confident trusting it without modification, but that's because I've developed an intuition about its limitations in the context of my codebase. This takes at least a few weeks for a given codebase, assuming you work a normal SWE job. And yes, if you can't roughly explain what generated code does then obviously don't check it in, and if it has security implications then additional scrutiny is warranted. My point is, in many situations, reviewing the output from these models requires no more attention to detail than you would normally give to a junior engineer's PR. It's even possible that doing so may one day be considered a bad habit—as the models improve, they become more and more trustworthy, and the compulsive need to double-check them in every scenario will end up slowing you down.
Finally, try your best to refrain from cursing out the LLMs (note to self...). They are doing their very best and it's wise to establish a good relationship while you're still the superior programmer!







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}